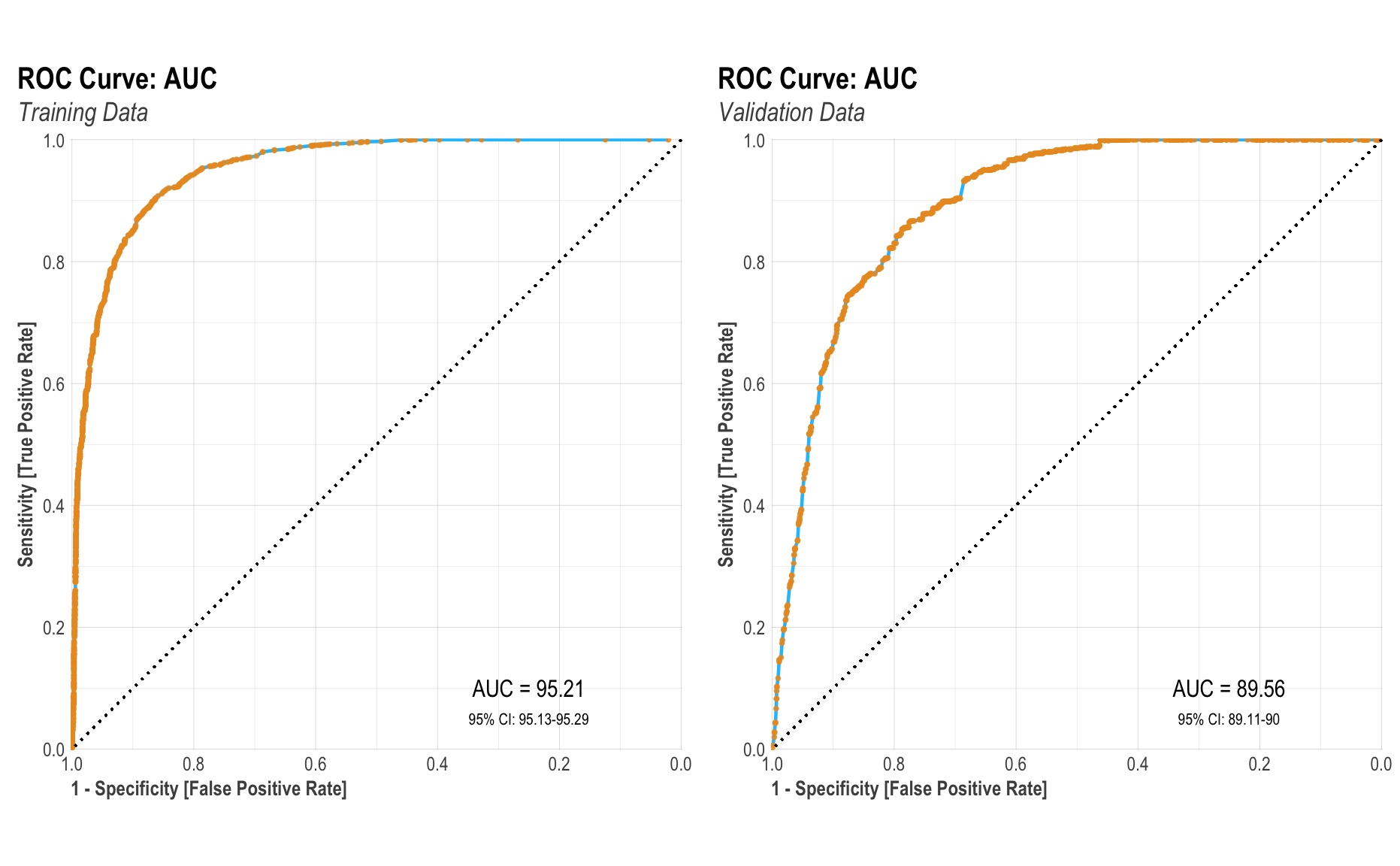
Development of Prediction Model for High-risk Sources and Seasons of C. Jejuni Outbreaks Identification
As part of a final project, I worked with two other students to create a prediction model using data from the NCBI Pathogen Detection Project, which is a large database containing Campylobacter jejuni isolate samples collected in the United States. Our goal was determine whether or not certain seasons or isolation sources, such as chicken or dairy, are associated with outbreaks of C. jejuni. Our final model had an AUC of 0.896, accuracy of 0.900, and Brier score of 0.073 on the validation set.
Differential Privacy: An Introduction
As a final project, I worked with one other classmate to develop a website introducing a machine learning concept that we had not learned in class-- differential privacy. Differential privacy is a solution– it enables us to publicly share information about a dataset, without actually revealing information about the individuals it consists of. Our website included a short article explaing how differential privacy works and why it's important, as well as tutorials for implementation in R and Python.

Introduction to Equivalence Trials
For a final project, I developed a report and presentation on the study design of equivalence trials. The goal of this project was to develop a methodological report that introduces a type of experimental design that was not discussed in class. While most have heard of superiority and non-inferiority trials, Unlike both superiority and non-inferiority trials, equivalence trials are a relatively rare type of study design that requires two active treatments to be identical within some predetermined acceptable range.
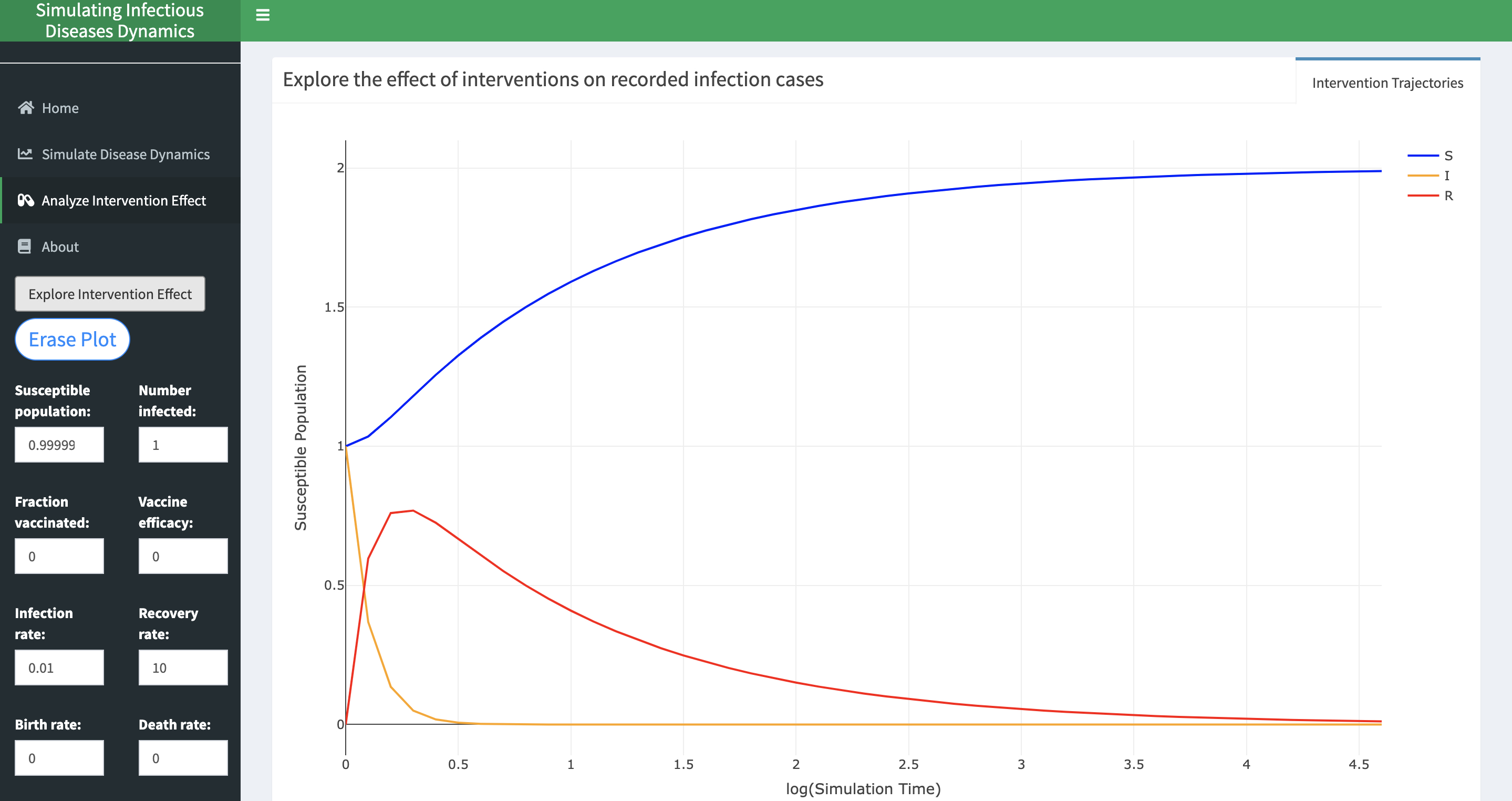
Infectious Disease Modeling R Shiny Application
I worked with two other classmates to develop an R Shiny application to provide users with a tool to create interactive and visual simulations of infectious disease dynamics. Under the current COVID-19 landscape, we felt that providing a means to model trends in disease spread and recovery over time may be beneficial for researchers and the general public. Features include the ability to adjust parameters manually and download the resulting simulation tables. The models we provided are commonly used in epidemiological research. In particular, we adopted the SIR equations found in Cooper (2020) and borrowed our intervention functions from an R package created by Andreas Handel.
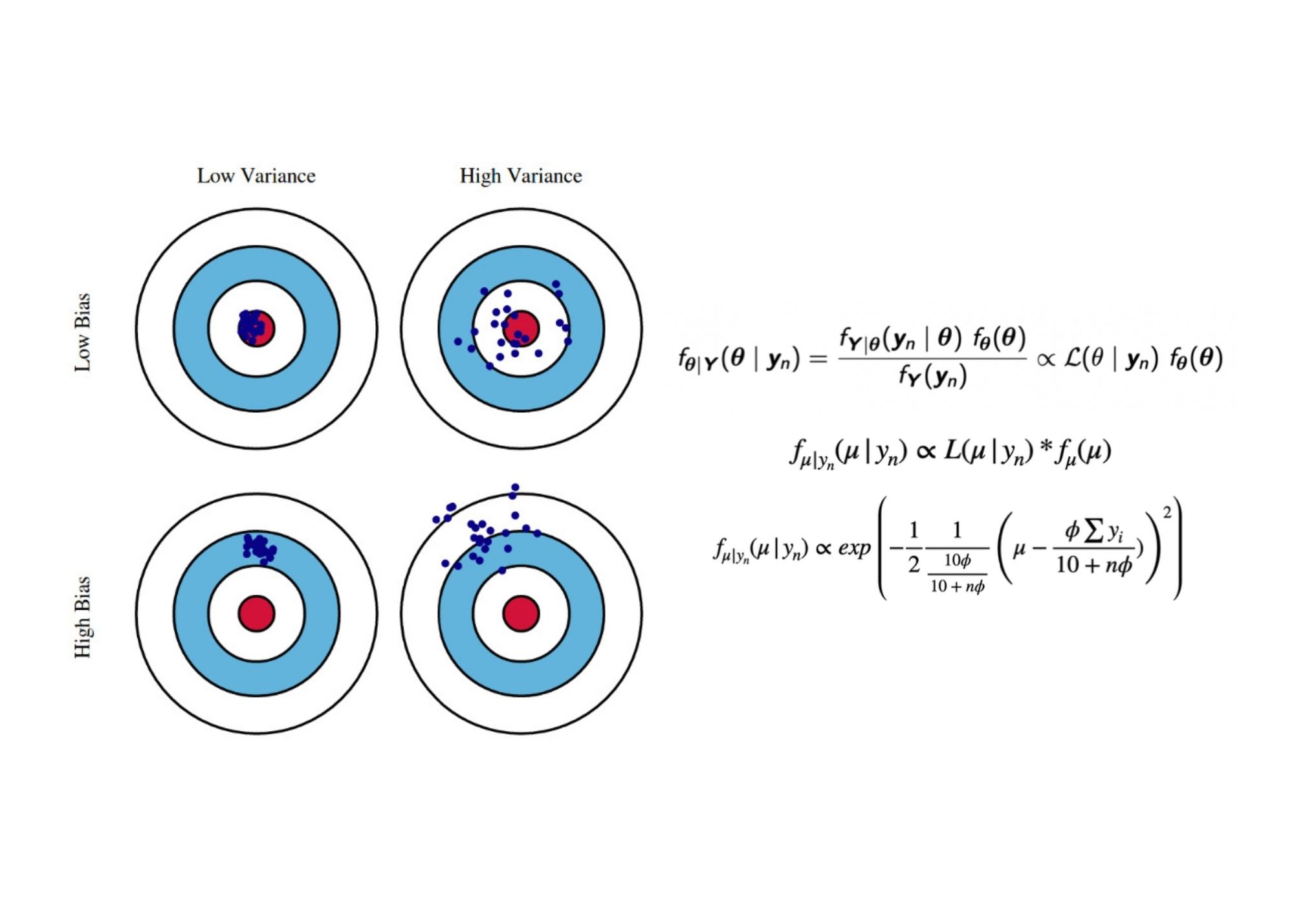
Bayesian Estimation and the Bias-Variance Tradeoff
As part of a final project, I worked with two other students on a presentation to demonstrate why unbiased estimators may not always be preferred through an examples that compares maximum likelihood estimators and Bayesian estimators, the latter of which can result in a lower mean squared error despite having a higher measure of bias than its counterpart. The popularization of this concept and of Bayesian estimators revolutionized the field of statistics during the 1980s and has found wide application in artificial intellgience and machine learning.