
Differential Privacy:
An Introduction
By Kyla Finlayson + Antonella Basso
For our project, we will be introducing differential privacy-- what it is, why it's useful, and how we can implement it in both R and Python.
What is differential privacy?
With the rise of technology and data, privacy has become incredibly important to both companies and individuals. Although big data has helped to bring about numerous breakthroughs within the healthcare industry, many of the datasets that both researchers and organizations use contain sensitive information about individuals. Differential privacy is a solution– it enables us to publicly share information about a dataset, without actually revealing information about the individuals it consists of.
So what exactly is differential privacy? Differential privacy, simply, is a system for adding random noise to each of our data observations so that our data does not reveal the information of any particular person or observation. As a result, there will always be some difference between the real observations and the differentially private ones– but in a way that does not inherently change the results from analysis of our data. It may be helpful in this case to consider the Law of Large Numbers, which states that as the number of random, identically distributed variables increases, the sample mean of our data will approximate the true population mean. Now consider that instead of having random, identically distributed variables, you add random, identically distributed noise to each observation in your dataset– the noisy mean will approximate the true sample mean.
We can imagine how this might work through a simple example. Say you are a researcher who is interested in analyzing data regarding a behavior that is illegal, taboo, personal, or for whatever reason would make individuals not want to have their answer be known or tied to their identity. Perhaps each individual in the data answered truthfully, therefore the data is not accessible to you due to a company’s privacy policy. In this case, you might suggest a differential privacy mechanism to analyze the data without being able to identify answers to specific individuals.
In this example, let’s say that the behavior we are looking to analyze is the proportion of people who pick their nose. Then, one way that we could implement differential privacy is by having each individual flip a coin. If the coin lands on heads, then their observation will be their truthful answer to whether or not they partake in the behavior, and if the coin lands on tails, then their answer will have a 50/50 chance of being either ‘yes’ or ‘no’, regardless of their true answer. In this way, each person in the data is allowed plausible deniability for their individual answer. While changing 50% of our observations to random variables may not be plausible in real applications– we can just think of this as an example of how individuals in a dataset could no longer be linked to their responses with certainty. As the number of true observations increases, the small amount of random noise we’ve added to the data has a smaller and smaller effect on the actual distribution of our data. Thanks to the Law of Large Numbers, our noisy data approximates the real data– while allowing individuals privacy.
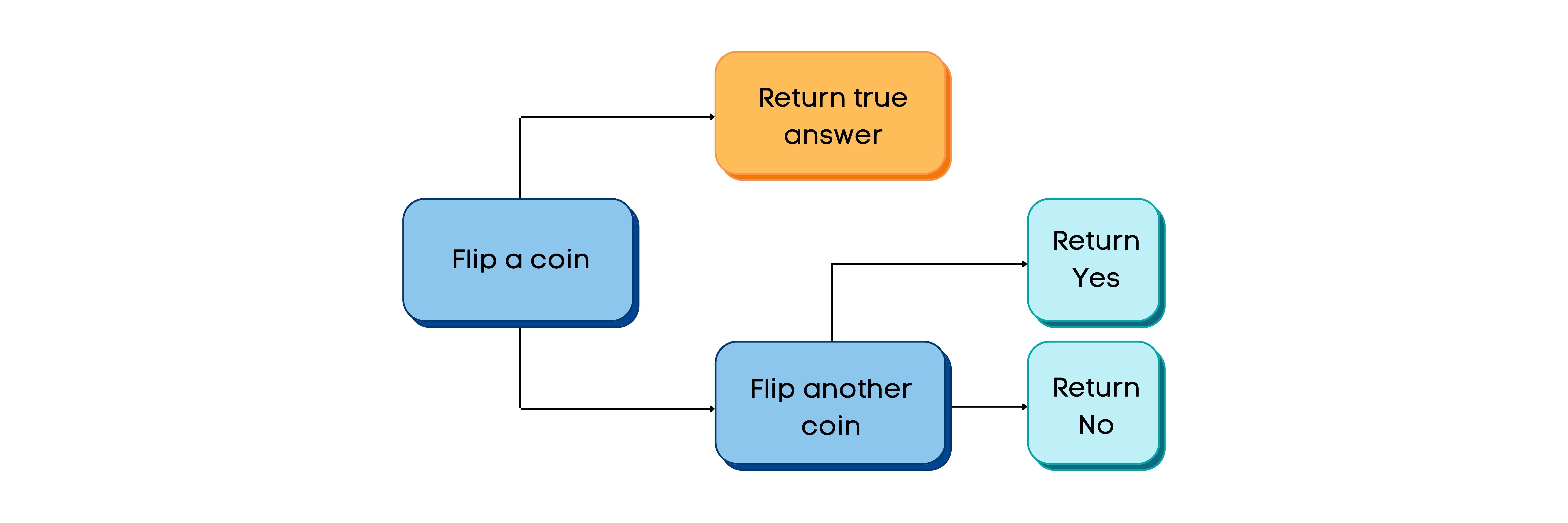
In reality, there are two important parameters that must be considered in differential privacy: epsilon (ε) and accuracy. Epsilon is defined as an arbitrary metric of privacy loss. The smaller epsilon is, the greater the privacy protection. Furthermore, the smaller the privacy protection is, the greater the accuracy of our data is. Essentially, in each differential privacy algorithm, there is an epsilon-accuracy tradeoff, where accuracy represents how close the output of our differentially-private algorithm is to the true output.
Noisy Proportions
Continuing with our silly example, let’s imagine a potential dataset of nose-picking proportions that we would like to add noise to to illustrate how differential privacy can be implemented.

The proportion that a researcher would like to estimate is 0.39, which is the ground truth, but our information is sensitive so we cannot exactly reveal the original dataset. Instead, we use a mechanism to add random noise to each of our observations that will not inherently change the distribution, but protect those who would prefer for their answers to be kept private. Often, with differential privacy implemented on numerical data, we would opt to choose a Laplace distribution in order to add noise. Suppose we choose a random number, X, which is randomly selected from a Laplace distribution with mean 0 and standard deviation 0.03, to add to each of our observations. In this case, each of our observations for “Yes” or “No” would be the true proportion plus a randomly distributed number from the Laplace distribution (p + L). This allows us to find a compromise between privacy and utilization. In essence, we want our researchers to be able to find useful information and knowledge from our data, but we don’t want them to be able to differentiate individual responses within our data. At this point you may be curious about the Laplace distribution and how greatly it would affect our observations. Below, you will find different distributions of the Laplace distribution, depending on the value of the mean and standard deviation. As we can see, it is similar to the normal distribution except it is much pointier– which is useful for choosing noise to add to our data.
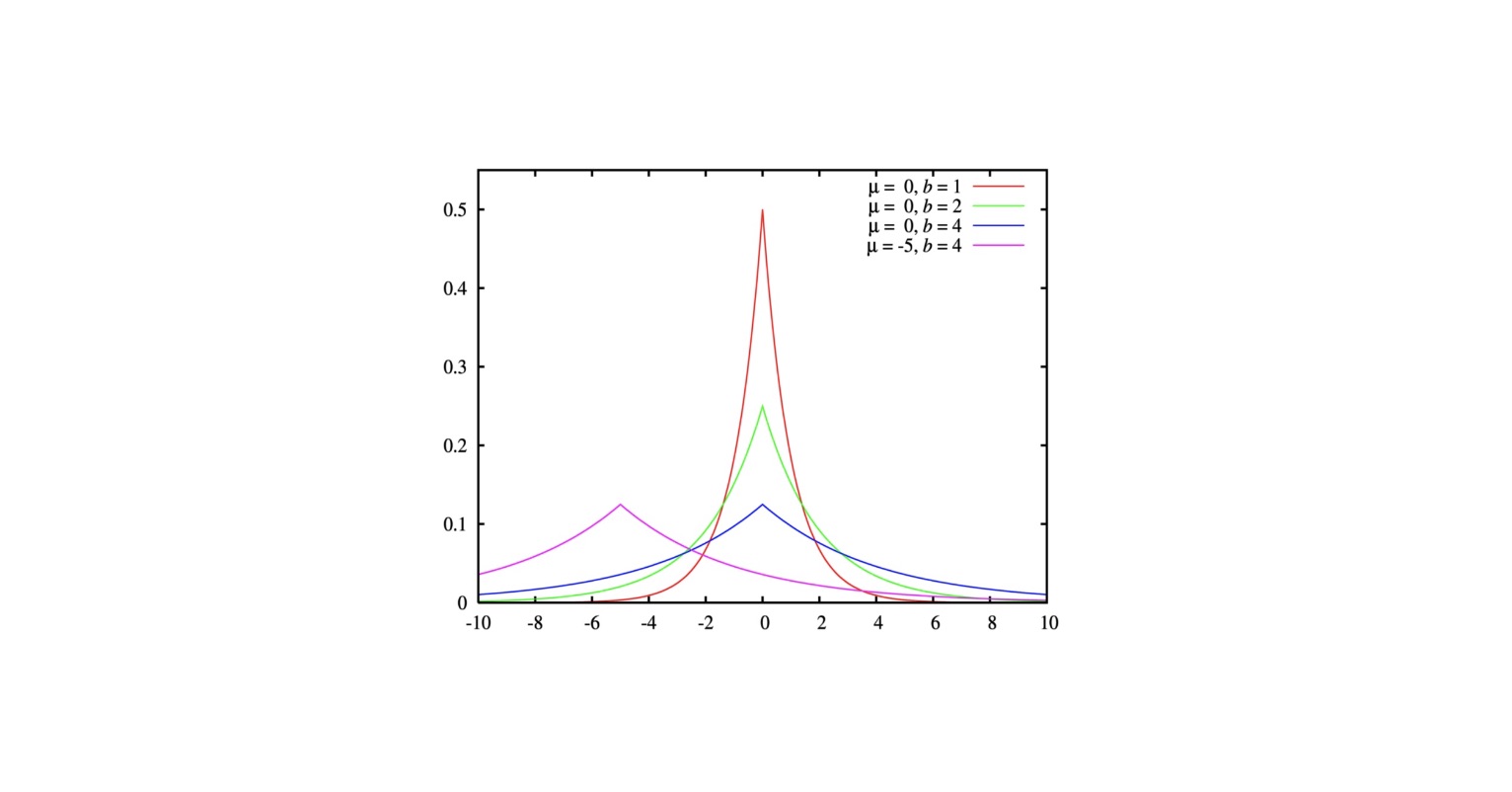
Source: Stephanie. (2021, November 30). Laplace distribution / double exponential. Statistics How To. Retrieved May 14, 2022, from https://www.statisticshowto.com/laplace-distribution-double-exponential/
Different Noise-Adding Mechanisms
Although we have already mentioned the Laplace mechanism, there are a few other noise-adding mechanisms that can be used to implement differential privacy, including both the Exponential and Gaussian mechanism. In general, we use the Laplacian mechanism to add noise to our data when the outcome is numerical and we use the Exponential mechanism to add noise to our data when the outcome is not-numerical. Simply enough, the Laplace mechanism works by adding noise to the output of our function, where the noise follows a Laplacian distribution. The Exponential mechanism is a little bit more complicated, but essentially it draws an output from a probability distribution, without actually adding noise to any of our data. The figure belows outlines the mechanism a little more clearly:

Source: Programming Differential Privacy. The Exponential Mechanism - Programming Differential Privacy. (n.d.). Retrieved May 14, 2022, from https://programming-dp.com/notebooks/ch9.html
The last commonly-used noise-adding mechanism is the Gaussian mechanism. Compared to both the Laplace and Exponential mechanisms, the Gaussian one is not very commonly used. It is used for numerical data and is very similar to the Laplacian distribution, the main difference being that the noise it adds is Gaussian and not Laplacian, which is useful for vector-value applications in which our L2 sensitivity is lower than our L1 sensitivity.
Privacy Deterioration
Lastly, we will go over the phenomenon of privacy deterioration– which is important to keep in mind when using differential privacy. If we are curious about the information a researcher would receive after querying our data, we would not be particularly worried. If a researcher were to make one query about our data and we provided them with our differentially private observations, there is a relatively small chance that said researcher would be able to infer anything about the individuals in our dataset. However, if a researcher were to make multiple or repeated queries in our data, we would begin to run into the limitations of differential privacy. In simple terms, as the number of queries increases, the greater the probability of our data/privacy being breached. This is one of the greatest limitations of differential privacy. As queries increase, the confidence interval that approximates the true target decreases, despite having random Laplacian noise added to each variable.

Source: Georgian Impact Blog. (2021, March 8). A brief introduction to Differential Privacy. Medium. Retrieved May 14, 2022, from https://medium.com/georgian-impact-blog/a-brief-introduction-to-differential-privacy-eacf8722283b
A Tutorial in R
Here, we will show a tutorial of how to implement differential privacy in R using the R package "diffpriv".